Letztendlich ist der relevanteste Wert der Wett-Tabelle und der anderen Zufallsindikatoren nicht der absolute Wert jedes Teams, sondern die Differenz der beiden Teams, die sich am nächsten Spieltag gegenüber stehen. Wenn wir beispielsweise den nächsten (17.) Spieltag der brasilianischen Serie A anschauen, ergeben sich für die anstehenden Paarungen folgende Differenzen für die drei Zufallsindikatoren (aus Sicht des Heimteams):
Die Zufallsindikatoren für die Partien des 17. Spieltags (aus Heimsicht)
| # | Heim | Gast | WTB | OTV+1 | OTV-S |
|---|---|---|---|---|---|
| 1 | Figueirense | Vitoria | |||
| 2 | Sport Recife | Atletico PR | |||
| 3 | Atletico MG | Santa Cruz | |||
| 4 | Fluminense | Ponte Preta | |||
| 5 | Sao Paulo | Chapecoense AF | |||
| 6 | Coritiba | Flamengo | |||
| 7 | Internacional | Corinthians | |||
| 8 | Santos FC | Cruzeiro | |||
| 9 | America MG | Gremio | |||
| 10 | Botafogo RJ | Palmeiras |
Im nächsten Schritt musst du nun die Standardabweichung berechnen[1]. Ein beliebter Fehler ist an dieser Stelle, lediglich die vorhandenen Paarungen zu berücksichtigen. Es ist allerdings wichtig, im Hinterkopf zu behalten, dass die Spieltagspaarungen nur einen Bruchteil der möglichen Begegnungen repräsentieren – für die Standardabweichung sind gleichermaßen diejenigen Begegnungen von Bedeutung, die nicht stattfinden, aber theoretisch möglich wären.
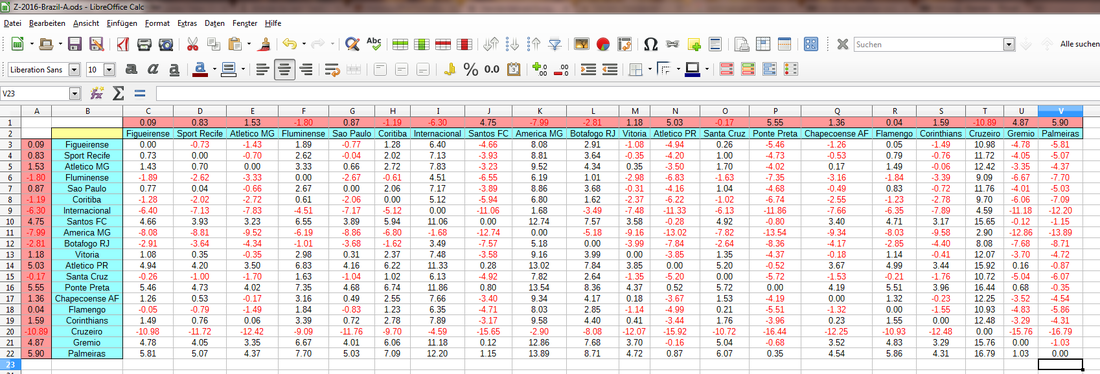
Zu diesem Zweck musst du in deinem Spreadsheet eine Matrix erstellen, die die Differenzen aller theoretisch möglichen Paarungen abbildet. Wie das funktioniert, zeige ich dir am folgenden Beispiel:
Eine Begegnungs-Matrix für alle Teams erstellen (am Beispiel der Wett-Tabelle)
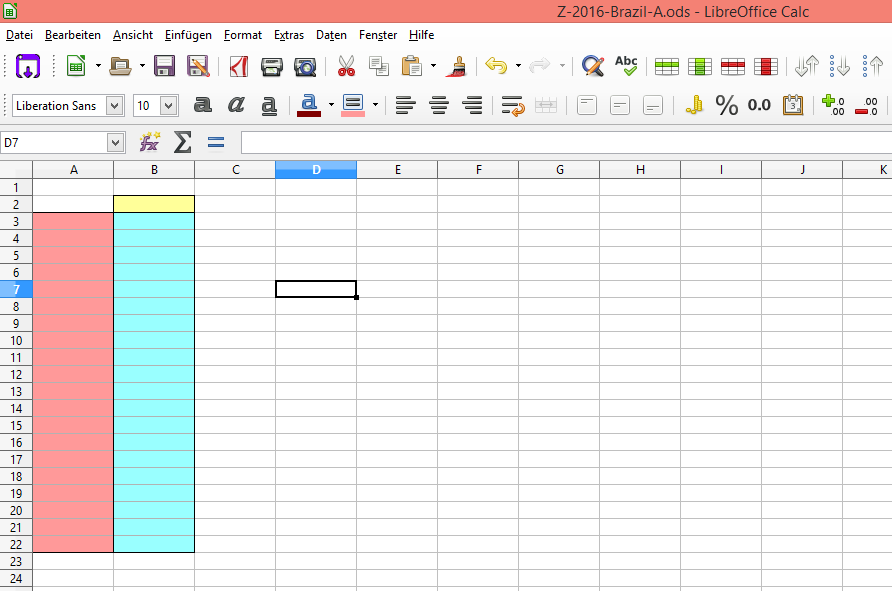
Schritt 1: Die Teams einfügen
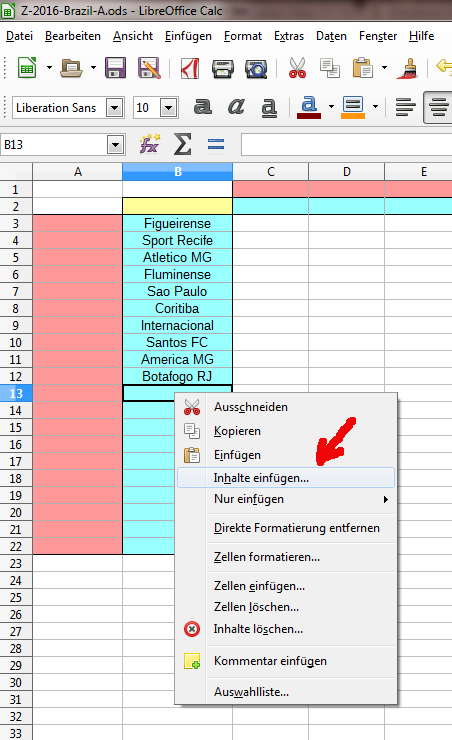
Schritt 2: Die Teamwerte einfügen
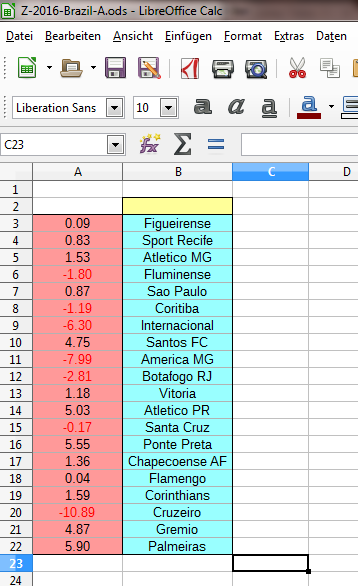
Schritt 3: Kopfzeile erstellen
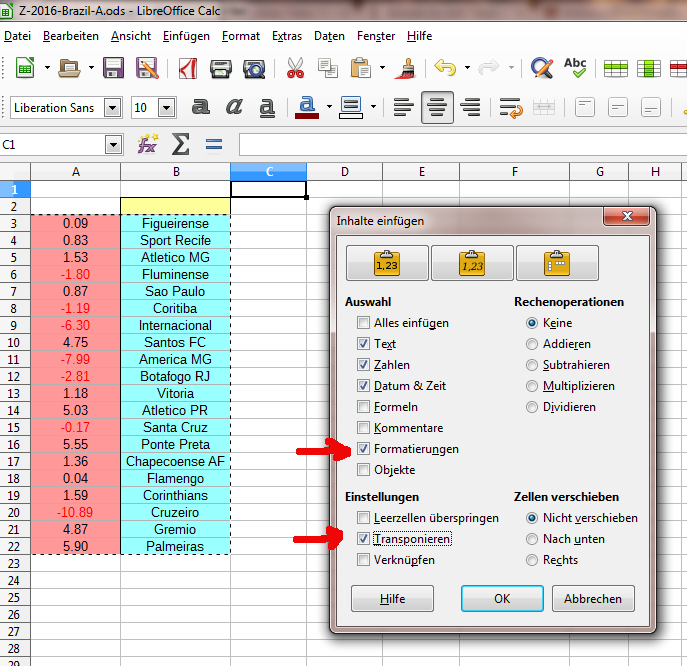
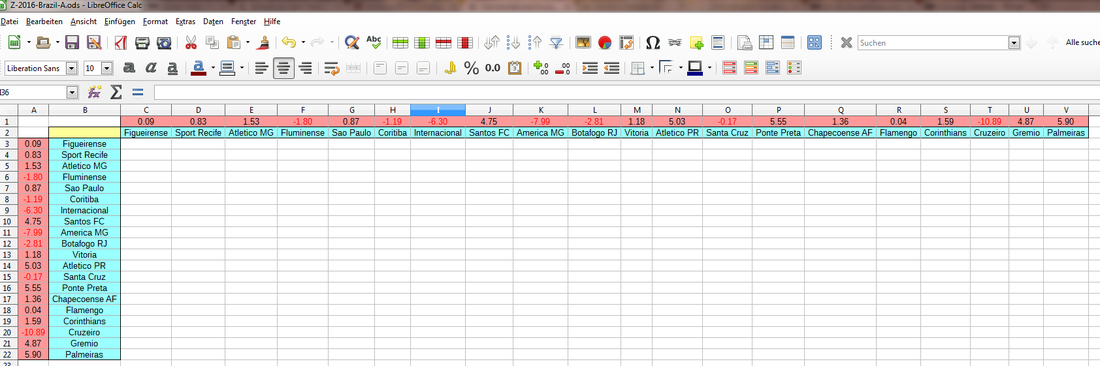
Schritt 4: Grundbaustein der Matrix
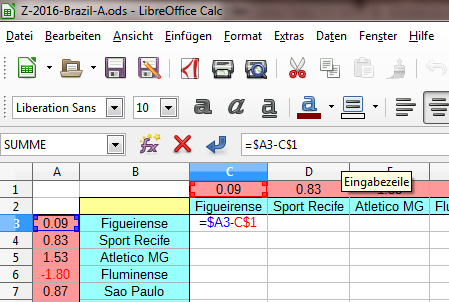
=$A3-C$1
Das Ergebnis für Zelle C3 selber lautet nun notwendigerweise 0, da hier der Wert von Figueirense mit sich selbst verglichen wird. Das muss überall dort in der Matrix der Fall sein, wo ein Team auf sich selber trifft. Das erste Dollarzeichen dient dazu, beim automatischen Auffüllen der Spalten D bis V den Buchstaben A konstant zu halten; entsprechend hält das zweite Dollarzeichen die Zahl 1 konstant, sobald du danach die Zeilen 4 bis 22 automatisch auffüllst.
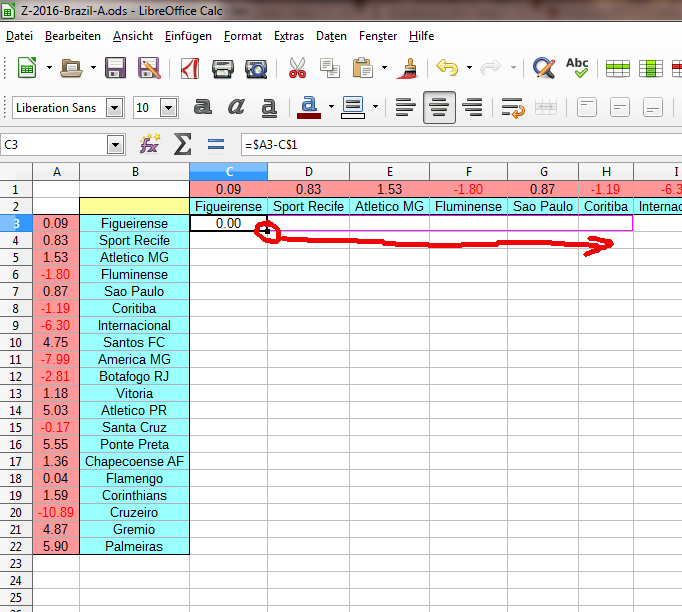
Schritt 5: Die Spalten der Matrix auffüllen
Schritt 6: Die Zeilen der Matrix auffüllen
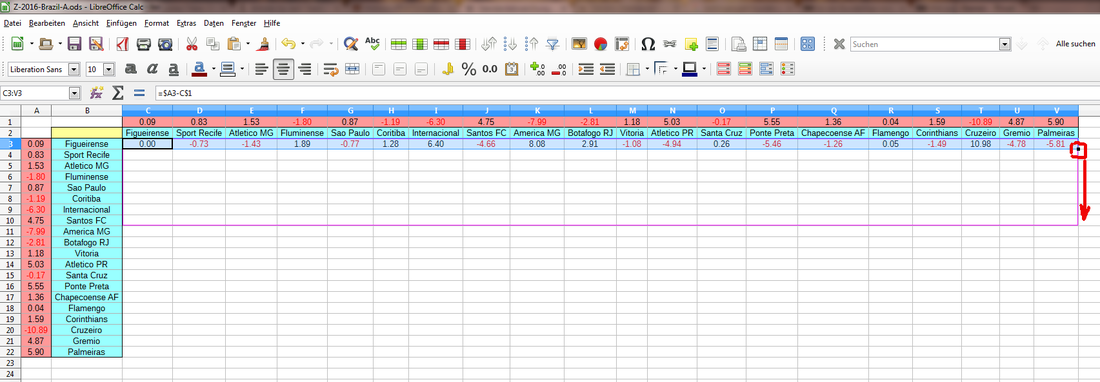
Schritt 7: Standardabweichung der Matrix berechnen
=STABW(C3:V22)
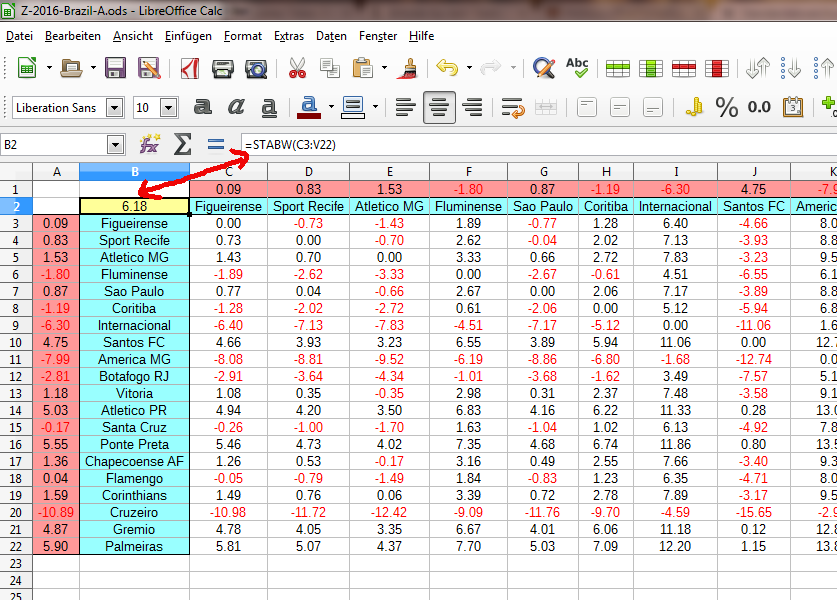
Die so berechnete Standardabweichung verwendest du nun, um zu sehen, wie extrem die Zufallswerte der kommenden Partien relativ zu allen möglichen Ligabegegnungen ausfallen.
Das erreichst du (wie eingangs erwähnt), indem du die Differenz der entsprechenden Partie durch die Standardabweichung teilst.
Die Quotienten für die Paarungen des 17. Spieltags (aus Sicht der Heimteams)
| # | Heim | Gast | WTB | OTV+1 | OTV-S |
|---|---|---|---|---|---|
| 1 | Figueirense | Vitoria | |||
| 2 | Sport Recife | Atletico PR | |||
| 3 | Atletico MG | Santa Cruz | |||
| 4 | Fluminense | Ponte Preta | |||
| 5 | Sao Paulo | Chapecoense AF | |||
| 6 | Coritiba | Flamengo | |||
| 7 | Internacional | Corinthians | |||
| 8 | Santos FC | Cruzeiro | |||
| 9 | America MG | Gremio | |||
| 10 | Botafogo RJ | Palmeiras |
Während der weitere Umgang mit diesen Indikatoren weiterhin Interpretationssache bleibt (wie das beim Fällen von Wettentscheidungen letztlich immer der Fall ist), hast du mit dem Ermitteln der Quotienten nun aber eine Möglichkeit, die relative Seltenheit der beobachteten Werte besser vergleichen zu können.
Interessant wird es insbesondere bei Werten oberhalb von +1 bzw unterhalb von -1. Größer als +1 bedeutet, dass das Heimteam in der entsprechenden Kategorie ordentlich Glück hatte verglichen mit dem Auswärtsteam, und das Umgekehrte gilt bei kleiner als -1.
Beim Blick auf die Paarungen des 17. Spieltags fällt also zum Beispiel auf, dass Ponte Preta recht viel Glück in allen Kategorien hatte verglichen mit Fluminense.
Das legt eine Wette auf Fluminense nahe, da das Team vermutlich eher unterbewertet werden wird vom Markt.
Fußnoten:
1 Die Standardabweichung berechnet sich aus der Quadratwurzel der Varianz. Diese berechnet sich aus dem quadrierten Abstand aller Werte zum Tabellenschnitt.
 RSS-Feed
RSS-Feed